I have just released a SQLite extension that wraps the C implementation of Roaring Bitmaps. By using this extension, you can create, manipulate and query roaring bitmaps write from within your SQLite queries. Why is that useful, you might ask? Well let me try to explain throughout this article.
What are roaring bitmaps?
I will not go into detailing the design and implementation of roaring bitmaps, but to give the reader a quick idea, roaring bitmaps are a special kind of bitsets, in that they are compressed to occupy much less space, while retaining most of the bitsets speed for doing logical operations.
Bitsets themselves are a way to represent numbers as individual bits in a large bit stream. For example the number 27 can be represented by flipping the 27th bit in a 4 byte long bit stream. As such
00000000 00000000 00000000 00100000 //bit #27 is flipped
While this looks like it doesn’t save us any thing, imagine a bit set with the numbers: 2, 4, 7, 14, 16, 21, 25, 27, 31
01010010 00000101 00001000 10100010 //bits matching our numbers flipped
There is more, imagine if we have two of these bitsets, we can quickly apply logical operations (e.g. AND, OR, NOT, XOR) on their contents.
Imagine the following problem, we have two bitsets A and F, bitset A has ids for countries that speak Arabic and bitset F has ids for countries that speak French, as follows:
10010010 00110010 11010000 10100110 //bitset A, 13 countries
01010110 01001110 11111010 01101011 //bitset F, 19 countries
Now we can very quickly answer the following questions
Countries that speak any of Arabic or French -> A OR F
11010110 01111110 11111010 11101111 //24 countries speak any of Ar or Fr
Countries that speak both Arabic and French -> A AND F
00010010 00000010 11010000 00100010 //8 countries speak both Ar and Fr
Countries that only speak one of Arabic or French -> A XOR F
1100100 01111100 00101010 11001101 //16 countries speak only one of Ar or Fr
How do roaring bitmaps differ from bitsets?
Bitsets can grow arbitrarily large to accommodate large numbers, imagine having a list with the number 1,000,000 alone. We will need a 31250 byte length blob to encode it. What if we want to have the number 1,000,000,000? We are talking mega bytes and eventually gigabytes to store large numbers that only consume 1 bit but the container bitset has to be that large.
Roaring bitmaps store bitsets in a compressed way, allowing the encoding of large numbers without having to store all the bits that precede it. More about how roaring bitmaps are encoded can be found in the repo linked above.
Using roaring bitmaps with SQLite
In order to use the roaring bitmap library, you need to load it into the SQLite connection, in the sqlite3 CLI app do
.load ./<path_to_lib>/libroaring
.load ./<path_to_lib>/carray
carray is a SQLite extension that is distributed with the SQLite source code, a compiled version for x86 Linux is distributed with RoaringLite. carray is not required for the operation of RoaringLite, but it enables exposing the bitmap as a virtual table for use in certain types of queries.
To test and benchmark roaring bitmaps we will need a data set to work with. Kaggle has us covered and we can use this dataset of ~350K quotes from good reads that is already implemented as a SQLite database that we can directly download.
The database comes with the following schema
CREATE TABLE QUOTES(
QUOTE TEXT PRIMARY KEY NOT NULL,
AUTHOR TEXT NOT NULL,
TITLE TEXT NOT NULL,
LIKES INT,
TAGS TEXT
);
So we have quotes with tags, which are represented as json arrays or sometimes with the string ‘None’ to indicate no tags for this particular code (sometimes an empty json array ‘[ ]’ as well).
Now what we want to do is to benchmark the following operations
- Count of quotes tagged with ‘life’ (a pretty common tag)
- Count of quotes tagged with both ‘life’ and ‘humor’ (AND)
- Count of quotes tagged with either ‘life’ or ‘humor’ (OR)
- Count of quotes tagged with only one of ‘life’ or ‘humor’ (XOR)
First method, using the LIKE operator
The first method would be to try and capture these numbers using the LIKE or GLOB SQLite operators, which is not expected to be pretty fast but it doesn’t require any extra storage. The queries will look like this:
SELECT count(*) AS c FROM quotes WHERE tags LIKE '%''life''%';
SELECT count(*) AS c FROM quotes WHERE tags LIKE '%''life''%' AND tags LIKE '%''humor''%';
SELECT count(*) AS c FROM quotes WHERE tags LIKE '%''life''%' OR tags LIKE '%''humor''%';
SELECT count(*) AS c FROM quotes WHERE tags LIKE '%''life''%' OR tags LIKE '%''humor''%' WHERE rowid NOT IN ( SELECT rowid FROM quotes WHERE tags LIKE '%''life''%' AND tags LIKE '%''humor''%' );
Second method, using FTS5
In this method we will create a minimalist fts5 table and use the fts5 query language to perform the queries. We create the table and populate it with data as such
CREATE VIRTUAL TABLE idx USING fts5(tags, detail='none', content='none');
--this is the smallest fts5 index we can possibly create
INSERT INTO idx(rowid, tags) SELECT rowid, tags FROM quotes WHERE tags != 'None'; -- insert tags into the index
We then used the following query to determine the size of the created index (after optimizing the index)
insert into idx(idx) values ('optimize');
select count(*)*4.0 / 1024 from dbstat('main') where name = 'idx_data';
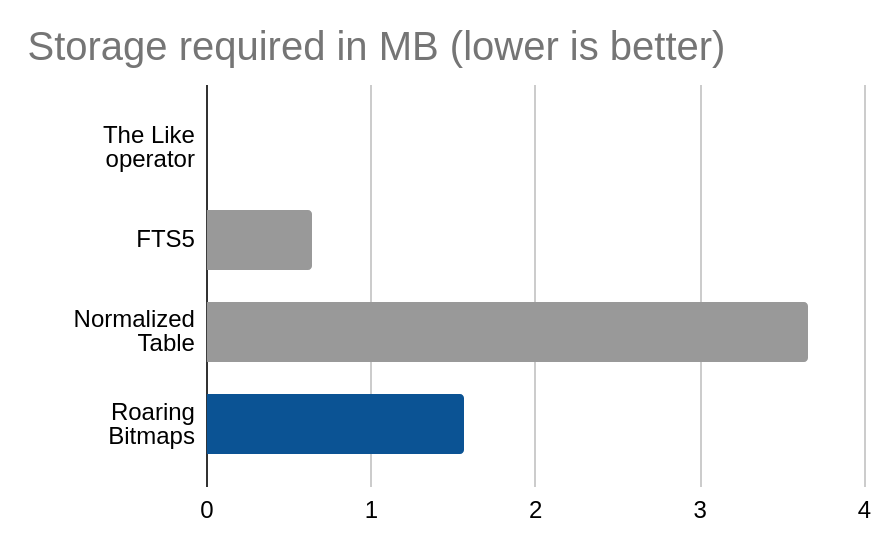
It turns out that the index costs us some 644KB which is really not significant at all
And then we can perform the queries as follows
SELECT count(*) FROM idx('life');
SELECT count(*) FROM idx('life AND humor');
SELECT count(*) FROM idx('life OR humor');
SELECT count(*) FROM idx('(life OR humor) NOT (life AND humor)');
These queries look the easiest on the eye so far!
Third method, a normalized table
In this method we break the json arrays and insert them in another table in a normalized manner, the schema for that table looks like this:
CREATE TABLE tags (tag TEXT, quote_id INTEGER, PRIMARY KEY(tag, quote_id)) WITHOUT ROWID;
We will basically have an entry per every tag, quote_id pair. We populate it using the following query:
WITH RECURSIVE extract(id, tag, rest) AS (
SELECT rowid, NULL, tags FROM quotes WHERE tags != 'None'
UNION ALL
SELECT id, rest ->> '$[0]' AS tag, JSON_REMOVE(rest, '$[0]') AS rest FROM extract WHERE JSON_ARRAY_LENGTH(rest) > 0
) INSERT INTO tags SELECT tag, id from extract WHERE tag IS NOT NULL;
Here we select each tags json array then recursively extract each tag from the array and insert every tag along with its rowid into the tags table.
The resulting table was measured to be using 3.66MB, which is not very large, but much larger than the fts5 version.
Now we can perform our queries as follows:
SELECT count(quote_id) AS c FROM tags WHERE tag = 'life';
SELECT count(*) FROM tags AS t1, tags AS t2 WHERE t1.tag = 'life' AND t2.tag = 'humor' AND t1.quote_id = t2.quote_id;
SELECT count(distinct quote_id) FROM tags WHERE tag IN ('life', 'humor');
SELECT count(distinct quote_id) FROM tags WHERE tag IN ('life', 'humor') AND quote_id NOT IN ( SELECT t1.quote_id FROM tags AS t1, tags AS t2 WHERE t1.tag = 'life' AND t2.tag = 'humor' AND t1.quote_id = t2.quote_id );
The queries are getting a bit more complex but we will see how they perform
Fourth method, Roaring Bitmaps
Here we will be utilizing the roaring bitmap extension, first we need to create the required table and populate it as follows:
CREATE TABLE roaring_tags (tag TEXT PRIMARY KEY, quote_ids BLOB) WITHOUT ROWID;
WITH RECURSIVE extract(id, tag, rest) AS (
SELECT rowid AS id, NULL, tags FROM quotes WHERE tags != 'None'
UNION ALL
SELECT id, rest ->> '$[0]' AS tag, JSON_REMOVE(rest, '$[0]') AS rest FROM extract WHERE JSON_ARRAY_LENGTH(rest) > 0
) INSERT INTO roaring_tags(tag, quote_ids) SELECT tag, rb_create(id) AS quote_ids from extract WHERE tag IS NOT NULL ON CONFLICT DO UPDATE SET quote_ids = rb_or(quote_ids, EXCLUDED.quote_ids);
We create a very simple table, one row per tag and a blob to store the bitmap in. Then we recursively traverse the tags and insert them and the row ids in place.
The size of the table was found to be 1.56MB, which is pretty smallish, even if larger than the FTS5 version.
We will use the following queries to extract the data we need for the roaring bitmaps table
SELECT rb_count(quote_ids) AS c FROM roaring_tags WHERE tag = 'life';
SELECT rb_count(rb_group_and(quote_ids)) AS c FROM roaring_tags WHERE tag IN ('life', 'humor');
SELECT rb_count(rb_group_or(quote_ids)) AS c FROM roaring_tags WHERE tag IN ('life', 'humor');
SELECT rb_count(rb_xor((SELECT quote_ids FROM roaring_tags WHERE tag = 'life'), (SELECT quote_ids FROM roaring_tags WHERE tag = 'humor')));
We don’t currently have an XOR aggregate function that’s why the last query look a little bit funky. Still the queries are quite readable though not as elegant as the FTS5 ones.
Benchmark results
Each of these queries was ran 100 times in succession in a single thread, then we collected the queries per second value. The connection was configured with a large page cache that exceeded the database size.
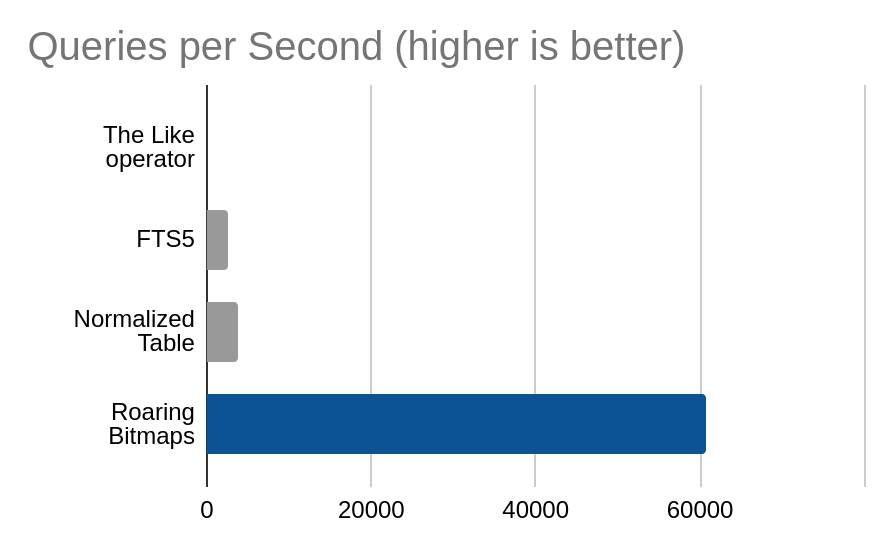
Count of quotes tagged with ‘life’
| Method | Queries per Second |
|---|---|
| The Like operator | 11.8 |
| FTS5 | 2568.7 |
| Normalized Table | 3808.9 |
| Roaring Bitmaps | 60792.4 |
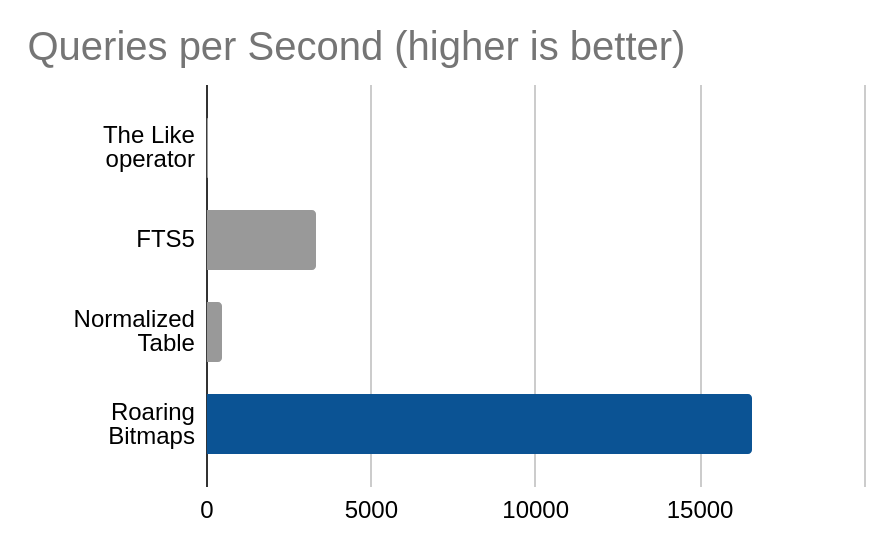
Count of quotes tagged with both ‘life’ and ‘humor’
| Method | Queries per Second |
|---|---|
| The Like operator | 12.1 |
| FTS5 | 3295.1 |
| Normalized Table | 459.6 |
| Roaring Bitmaps | 16594.4 |
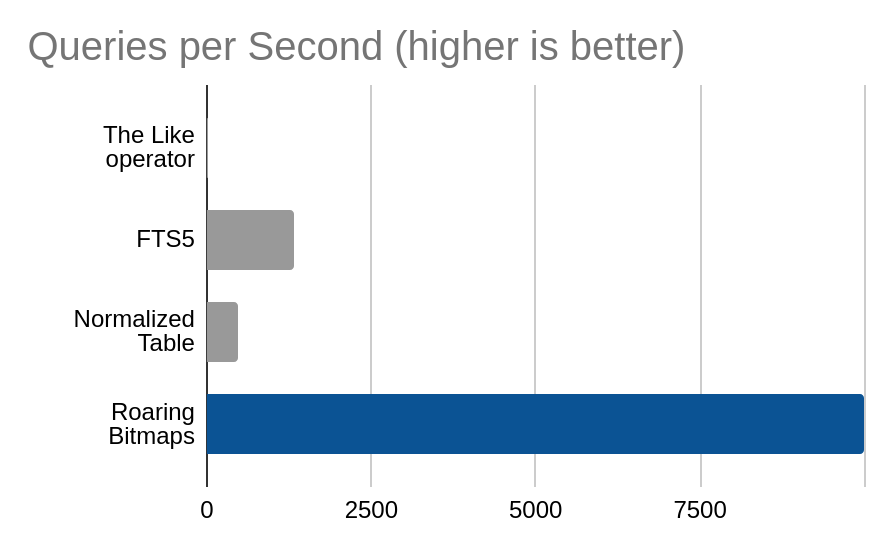
Count of quotes tagged with any of ‘life’ or ‘humor’
| Method | Queries per Second |
|---|---|
| The Like operator | 7.9 |
| FTS5 | 1338.0 |
| Normalized Table | 467.5 |
| Roaring Bitmaps | 9988.9 |
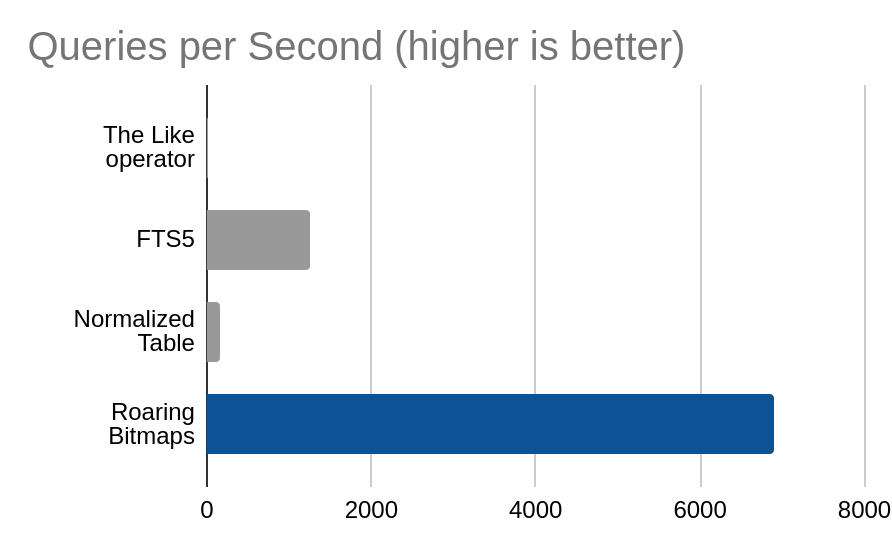
Count of quotes tagged with only one of ‘life’ or ‘humor’
| Method | Queries per Second |
|---|---|
| The Like operator | 4.9 |
| FTS5 | 1250.9 |
| Normalized Table | 169.5 |
| Roaring Bitmaps | 6901.6 |
Cost of each method in storage size
| Method | Storage size in MB |
|---|---|
| The Like operator | 0.00 |
| FTS5 | 0.64 |
| Normalized Table | 3.66 |
| Roaring Bitmaps | 1.56 |
Conclusion
Roaring bitmaps are plenty fast, and as can be seen, this does not happen at the expense of using too much storage. They cannot solve every SQL problem of course, but if you are trying to generate faceted distributions for data with sufficiently high cardinality (e.g. number of items with a certain star rating) they are hard to beat.
And this makes them a very nice complement to SQLite, where speed and efficiency are the norm. This is yet another piece of the puzzle in making SQLite one of the best platforms large dataset querying and analysis
An honorable mention goes to the FTS5 implementation, which manages to hold its own with very little storage overhead and absolutely no reliance of fancy SIMD instructions like roaring bitmaps do.

Leave a comment