Reading data from disk is a generally much slower process when compared to reading from memory. This is why almost all database management system will have some form of caching to keep some data nearby and reduce the expensive roundtrips to the storage media. SQLite is no different in that regard as it uses caching for this exact purpose. But, being embedded, SQLite behaves differently than most networked database solutions. In this article we will explore why is SQLite special when it comes to caching and how to get the best read performance from your SQLite databases.
If you are not interested in the technical details, you can skip to the benchmarks section.
Page caching primer
Most databases employ some sort of a page cache (called buffer pools in some circles). Which is essentially a replication of some of the pages that reside in the database file(s). Those caches are stored in memory and the help the database engine quickly find the data it needs. For example if the database is looking for a page that is not in the cache it will have to go through a lot of work until it gets it:
- Usually invoke the read() system call, which involves a switch to the kernel space
- The kernel then queries the VFS layer (Virtual File System) which could potentially have the data cached
- The VFS uses the specific filesystem driver (e.g. Btrfs or ZFS) and asks it for the data
- The filesystem will locate the required pages on disk and transfer the data to the kernel buffer
- The data is then copied to the user space buffer and control is switched back to the user application
Contrast that to the situation when the page exists in the page cache:
- Read the page from the page cache
If the page exists in the cache then we save ourselves two context switches, a memory copy, and a potentially very slow (relatively) read from the disk media. This really can make the difference between a fast query and a very slow one.
For SQLite, page cache can be managed using the cache_size pragma as such
PRAGMA cache_size = 100000 -- sets the cache size to 100K pages or 400MB
PRAGMA caceh_size = -400000 -- sets the cache size to 400K Kibibytes or 400 Mebibytes
Ok then, for SQLite, it seems all we need is to set the cache_size pragma high enough and queries will be very fast. Right?
Wrong!
There are two important considerations when dealing with page caches:
Page cache size
Memory is not for free, and the data stored in the database can grow to be very large. SQLite, being an embedded database, has no central memory space to store the page cache in, thus each connection uses private memory for the page cache, thus if you have multiple connections, potentially in multiple processes, you will have a private page cache for each connection (unless you are using the shared cache mode for connections in the same process, but this mode is being discouraged by the SQLite author).
Cache invalidation
We need to make sure only fresh data exists in the cache. If some update query changes the content of a page that happens to exist in the cache, this page needs to be refreshed to reflect the changes. On major issue with SQLite is that a connection cannot know what are the exact content (pages) that were modified/removed/added by other connections. It can only detect whether the file changed or not. This is why, whenever a connection writes to the database file, all other open connections have no option but to discard all their page caches, as they don’t know whether those pages in the cache are the most recent or not.
Now imagine a scenario where a SQLite database with many connections, each with a large page cache, all reading from and writing to the database very frequently, this will cause a lot of cache invalidation and will cause many queries to issue read system calls.
Still, it is important to note that SQLite also uses the page cache within the query execution process, and in that case no invalidation occurs mid query, hence, it is useful to have a page cache anyways such that if any page in a query is revisited it is not re-requested from the OS.
Enter mmap
Most modern operating systems offer a facility called Memory Mapped Files (mmap for short). These allow applications to request that a file, or a region of a file be mapped to main memory, in that case the application will see that mapped portion as if it is part of the process memory space, and it will read from it as it reads from other memory locations. The OS will be responsible for making sure that the data on disk is made available to process in that memory space when it needs it. It will also be responsible for ensuring that the data stays fresh and reflects the latest changes in these pages that were sent to the VFS layer, even if these changes were made by different processes.
SQLite supports mapping the database file (or parts of it) using the mmap_size pragma (which defaults to 0) to the desired mmap size in bytes as such
PRAGMA mmap_size = 419430400 -- set the mmap size to 400MB
By enabling mmap for your SQLite connection you get the behavior from your reads:
OS managed caching
Unlike the page cache, which is managed by the SQLite engine, which pages are pulled into the cache and which pages remain in it is completely controlled by the OS itself. If many mmaps are present in the system and they compete for the main memory then the OS will decide which pages gets evicted from which map. Modern Linux kernels (6.1+) include features that greatly improve mmap eviction strategies under high memory pressure.
Shared memory across connections
SQLite uses shared mmaps, which means that connections in different processes will be referring to the same memory thus preventing the duplication of the cache we see with page cache.
Transparent consistency
Unlike the SQLite page cache, which needs to be fully invalidated even if a single byte in the database file changes, the mmap’s consistency is handled by the OS itself, and it ensure any written page is atomically reflected in all processes that access the mmap. This means that if multiple processes are reading and writing from the database, the mmap will not be invalidated as with the page cache.
Some mmap caveats
Max mmap size
When setting your mmap_size, you will not be able to exceed the 2GB size for the mmap, which the default max value on 64bit platforms. You can increase that via the SQLITE_MAX_MMAP_SIZE compile time option
Pre-warming the mmap
If you have a large database, it may take quite some time before the data populate the mmap. If you need to warm the mmap early on, you can use the mmapwarm sqlite extension (distributed with the SQLite source code, in the /ext/misc folder) to populate mmap. This is a C function though but hopefully I will create a SQLite extension wrapper for it soon.
Better loading/eviction strategy
If you are on Linux kernel 6.1 or greater, you might want to rebuild the kernel with the following configuration options to enable the new MGLRU (Multi-Generational Least-recently-used) mmap management strategy:
CONFIG_LRU_GEN=y
CONFIG_LRU_GEN_ENABLED=y
Benchmarking and evaluation
We are going to have a look at the impact of both the cache_size and the mmap_size pragmas on query performance. We will have the following configurations tested:
- No cache and no mmap (both set to 0)
- Sizable cache (30% of the db size), no mmap
- Big enough cache to hold the db in memory, no mmap
- Sizable mmap (30% of the db size), no cache
- Big enough mmap to hold the db in the map, no cache
- Rerun configurations 3 and 5 in multiple process, along with an update query
The following query was run against a ~170MB database:
SELECT avg(length(body)) FROM (SELECT body FROM comments UNION ALL SELECT body FROM posts); -- force a table scan on comments and posts
For test #6, we also used the following query to trigger cache invalidation:
UPDATE users SET password = hex(randomblob(5)) WHERE id = 1; -- invalidate the cache
The tables are populated as follows:
- 10K records in the users table
- 100K records in the posts table
- 1M records in the comments table
We will be using Litedb, the SQLite3 adapter from the Litestack Ruby gem to issue the queries. This can be done in the SQLite3 console as well but using Ruby allows for flexibility in running certain repetitions of the queries, we will target around 10 repetitions per query (or 10 reads + 5 writes for test #6).
Important note regarding the filesystem cache
There are multiple caching layers for files, and we will not be able to isolate the effect of the mmap and page cache alone, since the filesystem does have a caching layer as well and it will influence the results, but we tried to make the effect uniform on all the tests by running the following shell command to drop all system caches:
sudo sysctl -w vm.drop_caches=3
Benchmark results
Read test (single process)
| Configuration | Average query execution time (ms) |
|---|---|
| cache_size = 0 mmap_size = 0 | 498.81 |
| cache_size = 50MB mmap_size = 0 | 512.37 |
| cache_size = 250MB mmap_size = 0 | 331.86 |
| cache_size = 0 mmap_size = 50MB | 439.54 |
| cache_size = 0 mmap_size = 250MB | 334.48 |
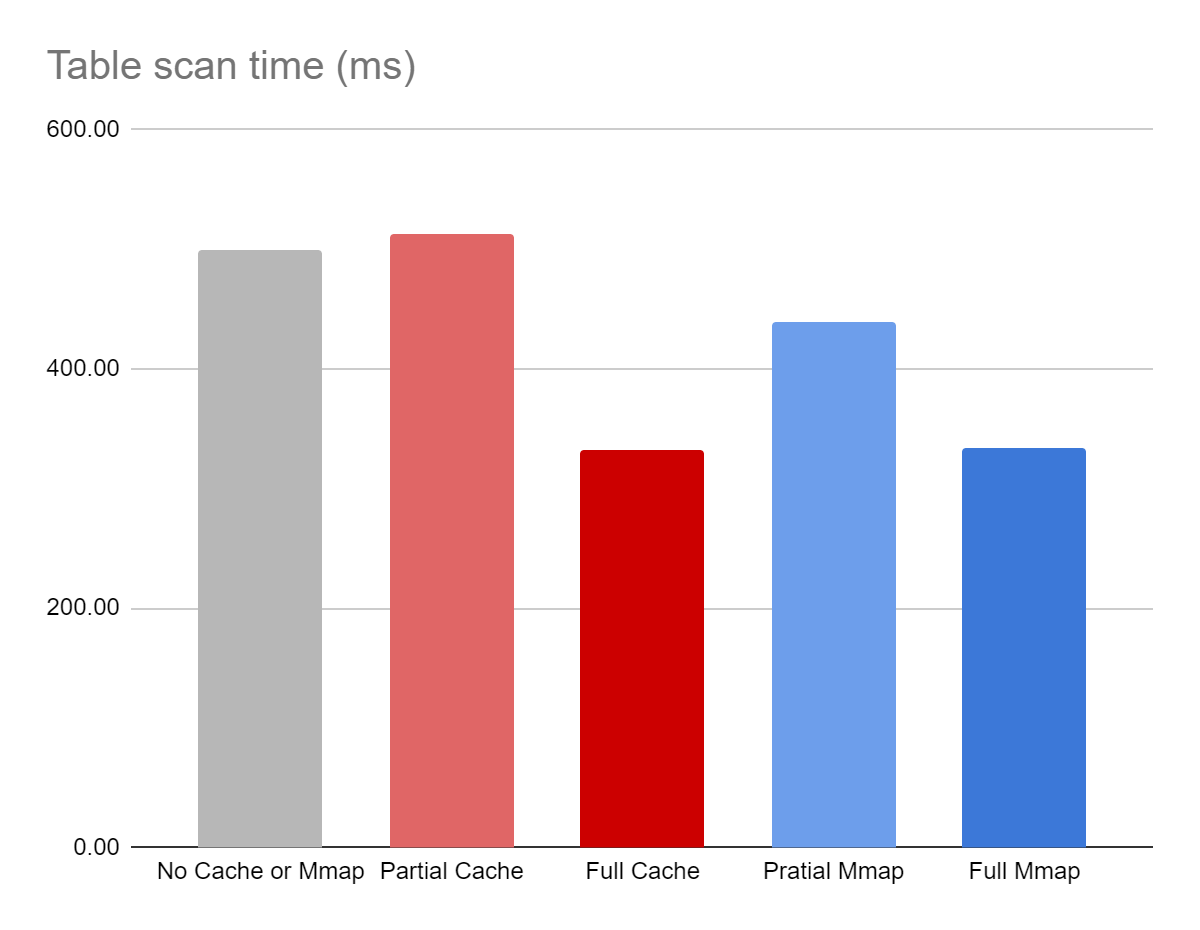
It is clear from the data that have a cache accelerates the queries considerably (this is a little muted in this benchmark due to the effects of filesystem caching). But there are a few noteworthy observations:
- A partial page cache performs worse than no cache! this is mainly due to the simplistic algorithm that SQLite uses to populate evict the cache, which is seemingly agnostic of the data access pattern
- Pratial mmap is an improvement over no cache, which is potentially the result of how the OS decides which pages to load (or preload) and which to evict.
- A big enough cache is the fastest, with a big enough mmap coming as a close second
Read/Write test (8 processes)
| Configuration | Avg query time (ms) |
|---|---|
| Full cache | 344.73 |
| Full mmap | 252.50 |
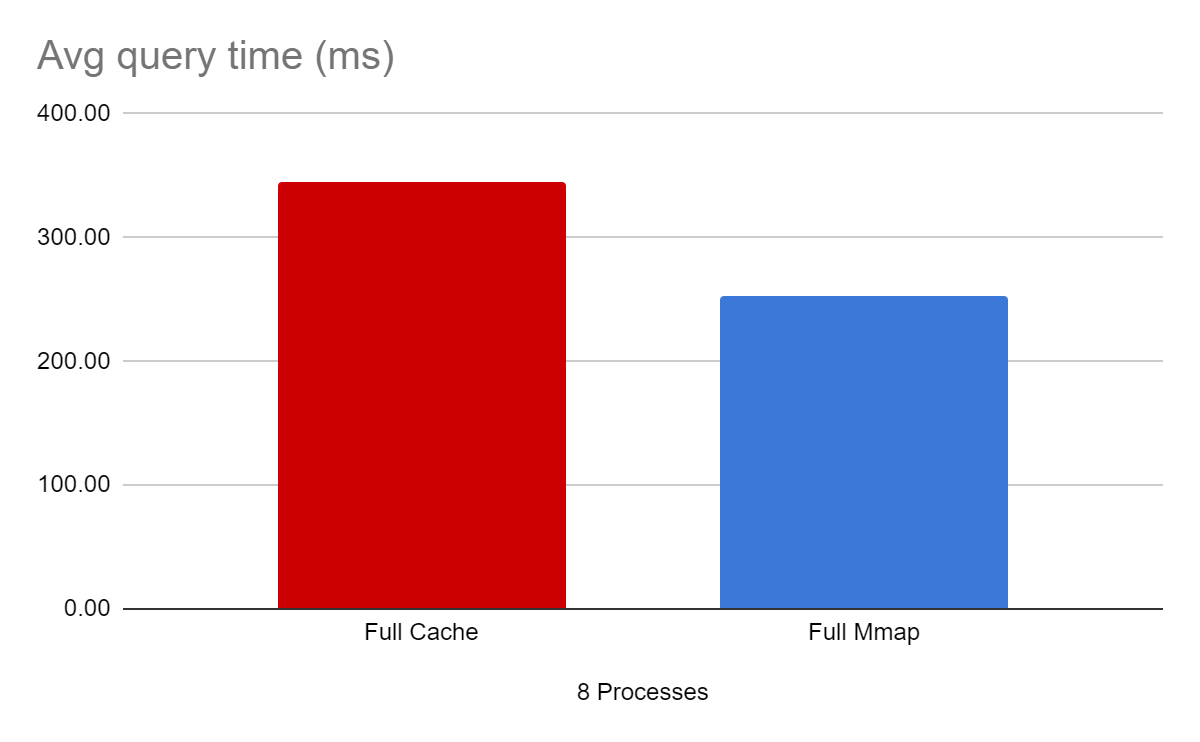
When writes are multiplexed with reads from multiple processes we see the mmap configuration outperforming the page cache configuration by over 36%!. As we mentioned earlier, this is due to the cache invalidation happening in the page cache version.
Memory usage (8 processes)
| Config | Resident RAM | Shared RAM | Total RAM |
|---|---|---|---|
| Full cache | 207 | 7 | 1607 |
| Full mmap | 168 | 149 | 301 |
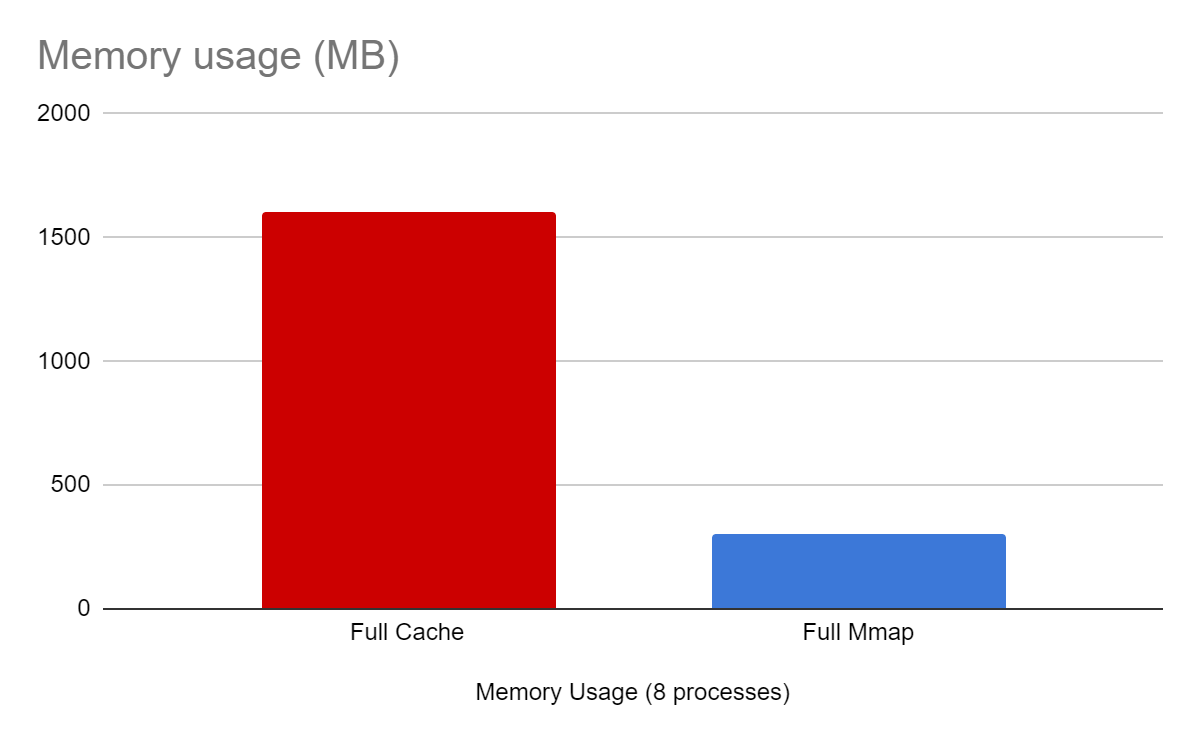
Not only is the mmap configuration faster, but it also uses way less memory. Thanks to the memory sharing by the mmap.
The total memory used is calculated as follows:
total_memory = (resident_memory – shared_memory) * process_count + shared_memory
Conclusion
Don’t use mmaps if you are accessing your database exclusively from a single connection in a single process. In all other situations mmaps is most likely the better choice.
Increase the size of your mmap as much as your system and your other apps allows. Litedb sets the mmap to 128MB by default, you would want to increase that when your database grows beyond that point.
Note that you shouldn’t set your page cache size to zero still, you need that for caching pages within transactions, but you might get away with leaving it at the default value or a little higher, this is what Litedb does by default as well.
In summary, when the infamous Andy Pavlo and friends ask you: Are you sure you want to use mmap in your database management system? Given that you are using SQLite, your answer should be a resounding YES!

Leave a comment